본 내용은 인프런 김영한 강사님 JPA 기본 편 강의를 듣고 정리한 내용입니다.
https://www.inflearn.com/course/ORM-JPA-Basic
자바 ORM 표준 JPA 프로그래밍 - 기본편 강의 - 인프런
회사땜에 매일 바쁜 와중에 학원이라도 다닐까 생각했는데 마침 JPA 강의가 생겨서 꿀 타이밍이네요. 저는 이 전에 JPA 책을 보고 공부 했었는데요 궁금했던 점, 업무에 적용하며 고민하고 해결하
www.inflearn.com
기본 키 매핑
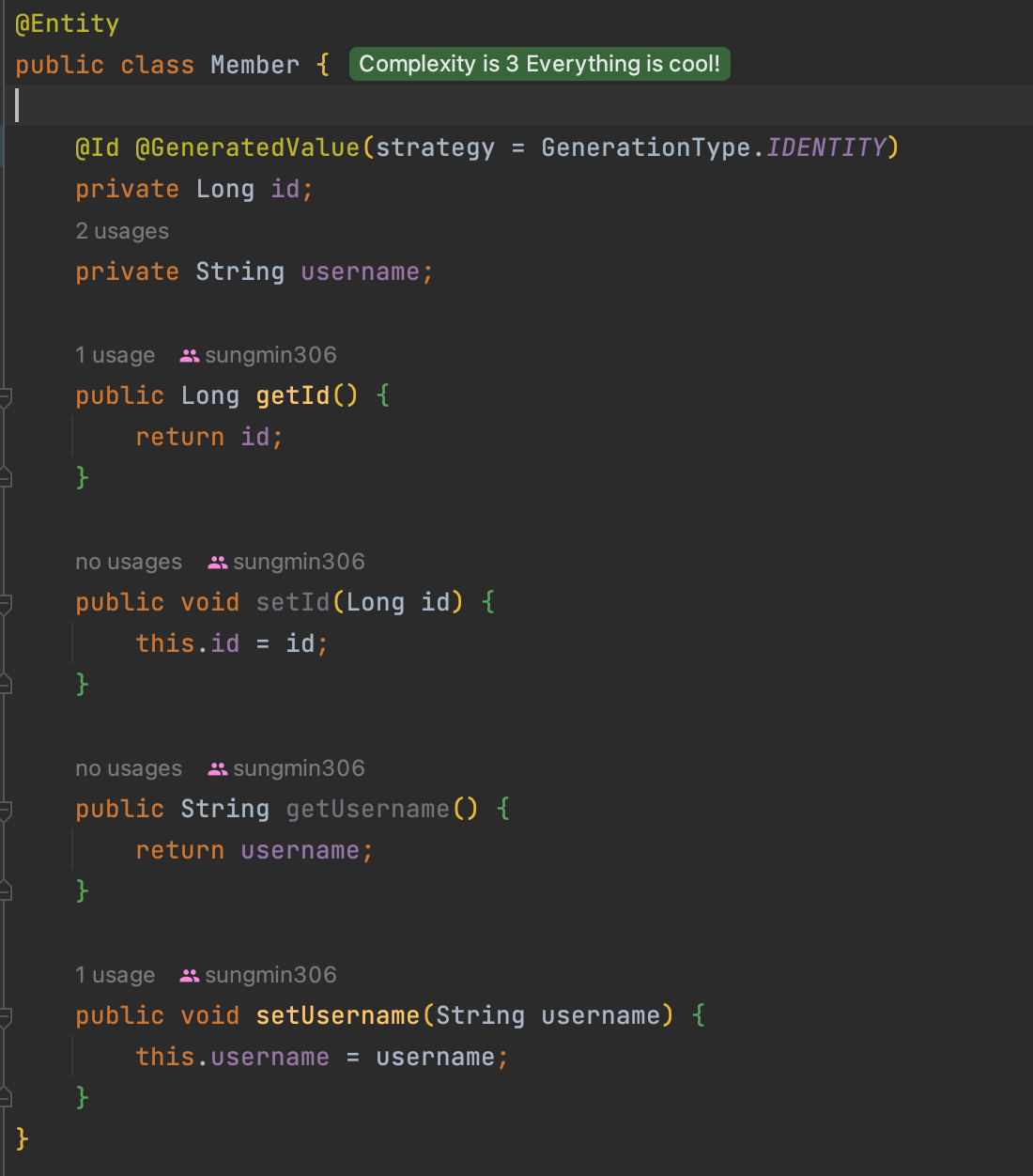
직접 할당할 경우 @Id 만 사용한다.
자동 생성
- IDENTITY
-SEQUENCE
-TABLE
-AUTO
IDENTITY
기본 키 생성을 데이터베이스에 위임 ( 주로 MySQL, PostgreSQL, SQL Server 등 사용) MySQL AUTO_INCREMENT 유사
그럼 한 가지 의문점이 생길 수 있다.
commit() 시점에 쿼리가 날아갈 텐데 그전에 Id를 어떻게 알 수 있을까?
-> IDENTITY는 그래서 commit()이 아닌 persist() 시점에서 쿼리가 날아간다.
실제 코드를 보자
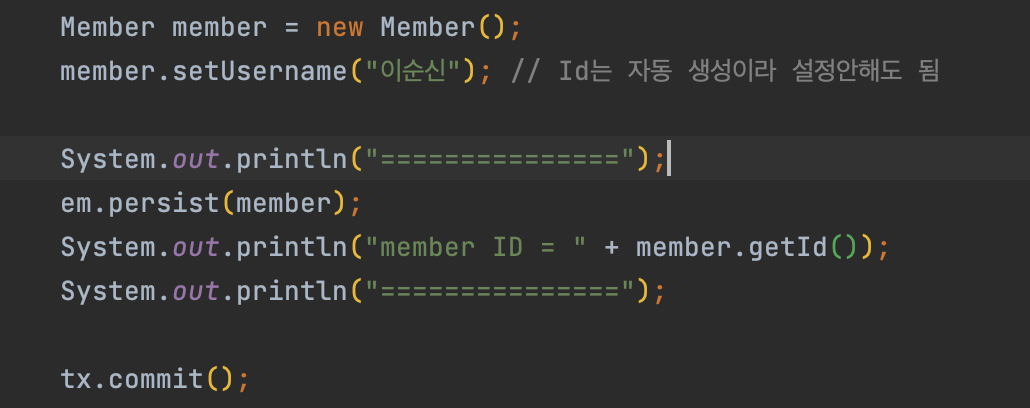
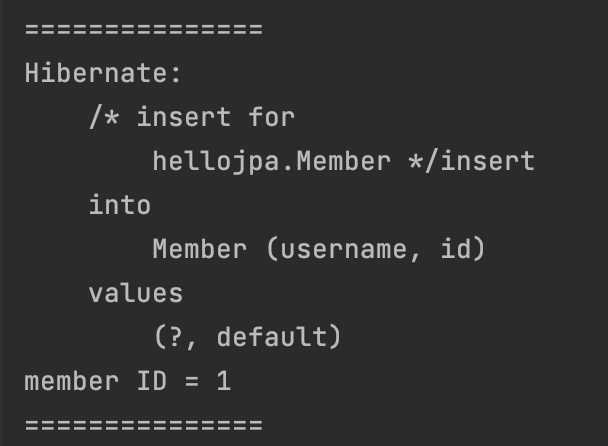
위 코드처럼 persist에서 쿼리가 발생하는 것을 볼 수 있다. 아이디 값 역시 잘 찾아오는 것을 볼 수 있다.
이렇게 됐을 때 트렌젝션에서 버퍼에서 모아서 한 번에 쿼리문을 보낼 수 없는 점은 존재한다(그러나 성능에 큰 영향을 끼치지는 않는다.)
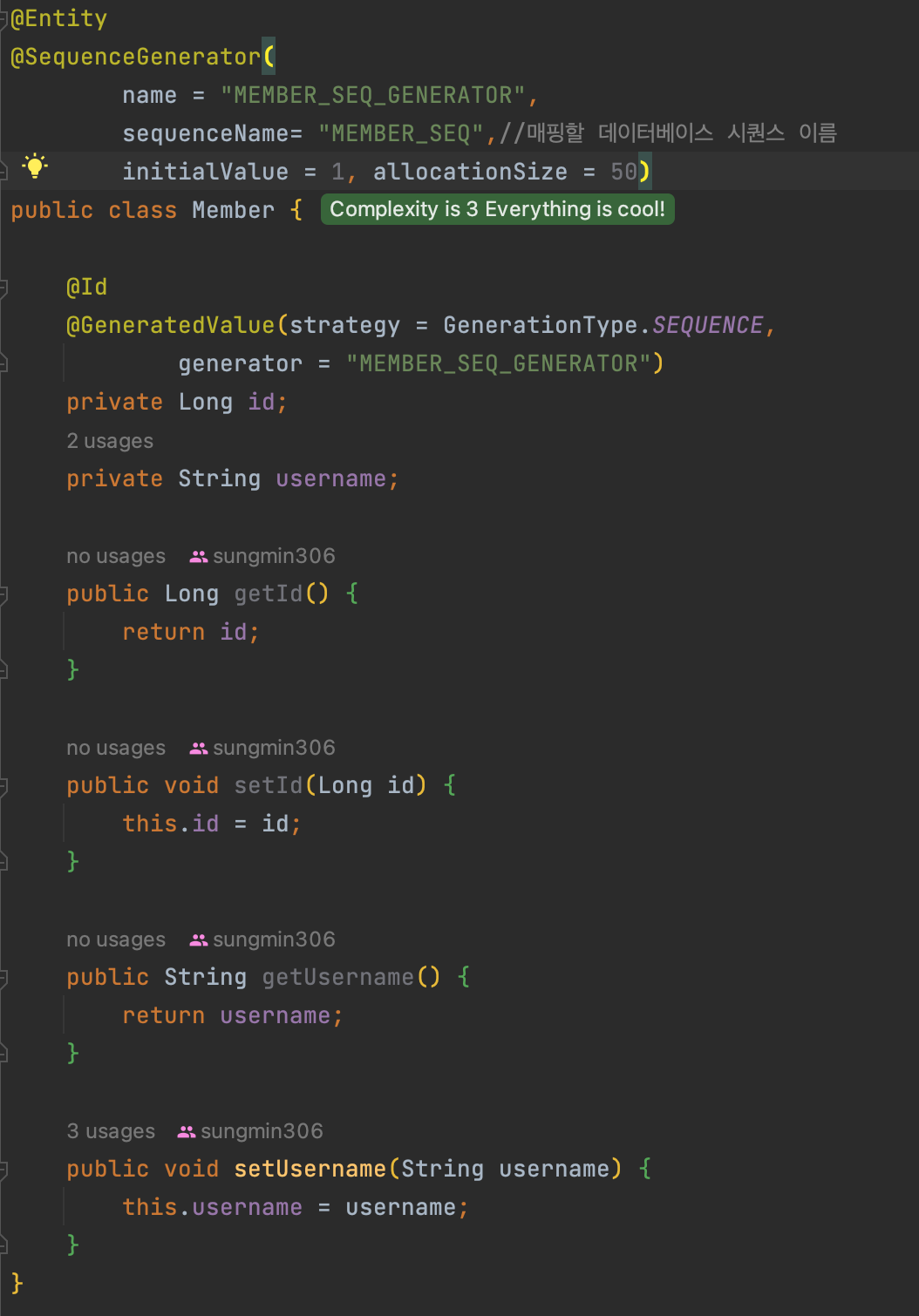
SEQUENCE
유일한 값을 순서대로 생성하는 특별한 데이터베이스 오브젝트(오라클, PostgreSQL, DB2, H2 데이터베이스에서 사용)
이거는 IDENTITY와 동작하는 방식이 다르다.
SEQUECE는 persist()에서 쿼리를 날리지 않는다. 시퀀스로 했을 때, 디비 시퀀스 값을 가져오고 나서 해당 값을 사용하는 식으로 한다.
이걸 설정하는 게 allocationSize이다.
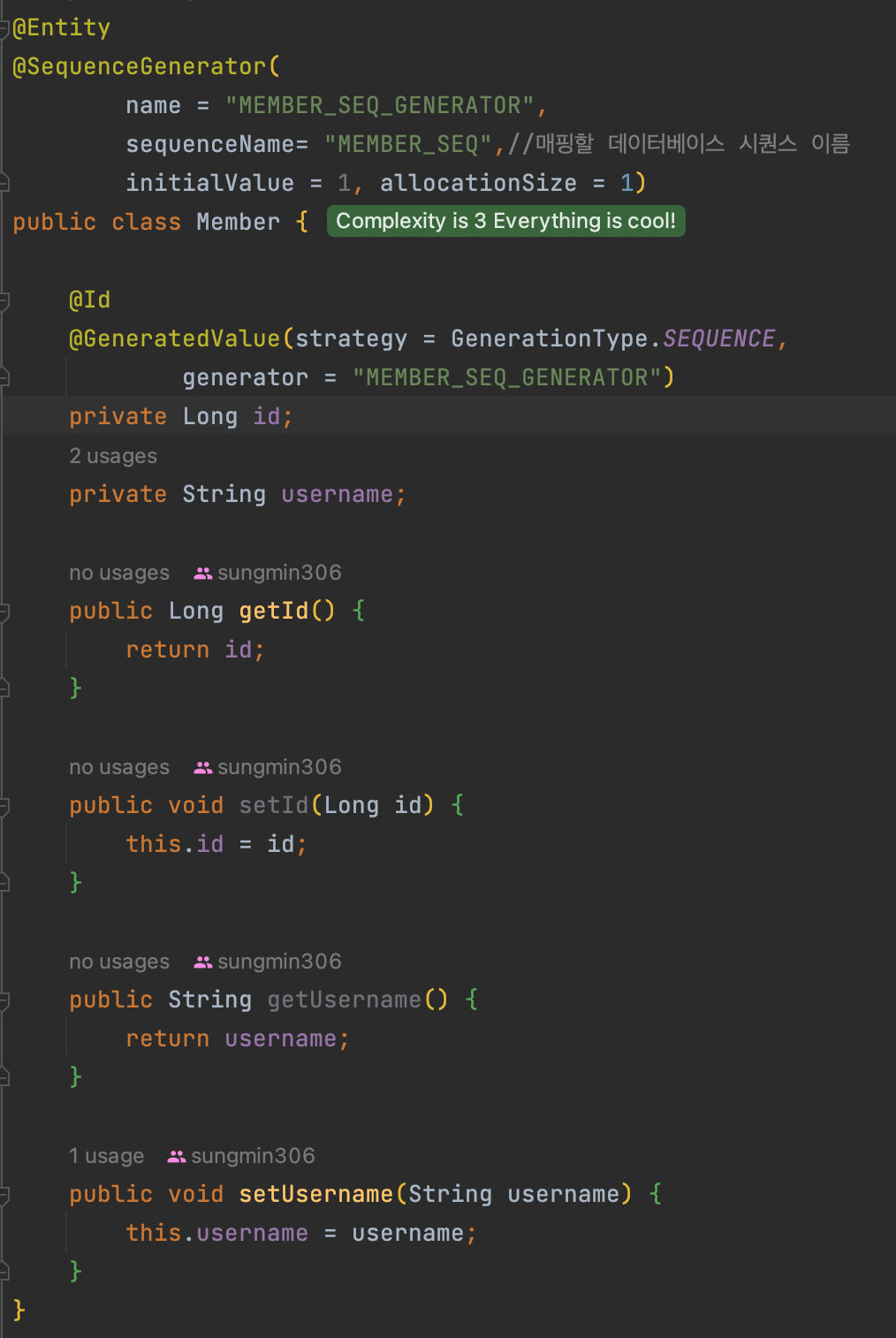


보이는 것처럼 insert 쿼리는 commit() 시점에서 날아가는 것을 알 수 있고, 맨 위에 MEMBER_SEQ 1은 엔티티에서 설정한 대로 되는 것을 볼 수 있다.
이 SEQUENCE 방식에서 재밌는 점은 allocationSize의 기본값이 50이다. 이게 왜 50이냐면 처음에 50개를 한 번에 가져오고 나서 이후에 50개를 또 가져와 메모리에 두고 ID 값을 미리 가져와서 사용한다. 이렇게 됐을 때 id 값을 계속 시퀀스에서 가져오는 식으로 하지 않아도 되기에 버퍼에 저장했다가 동시에 쿼리를 날릴 수 있다. 또한 동시성 연동에도 문제가 없다.
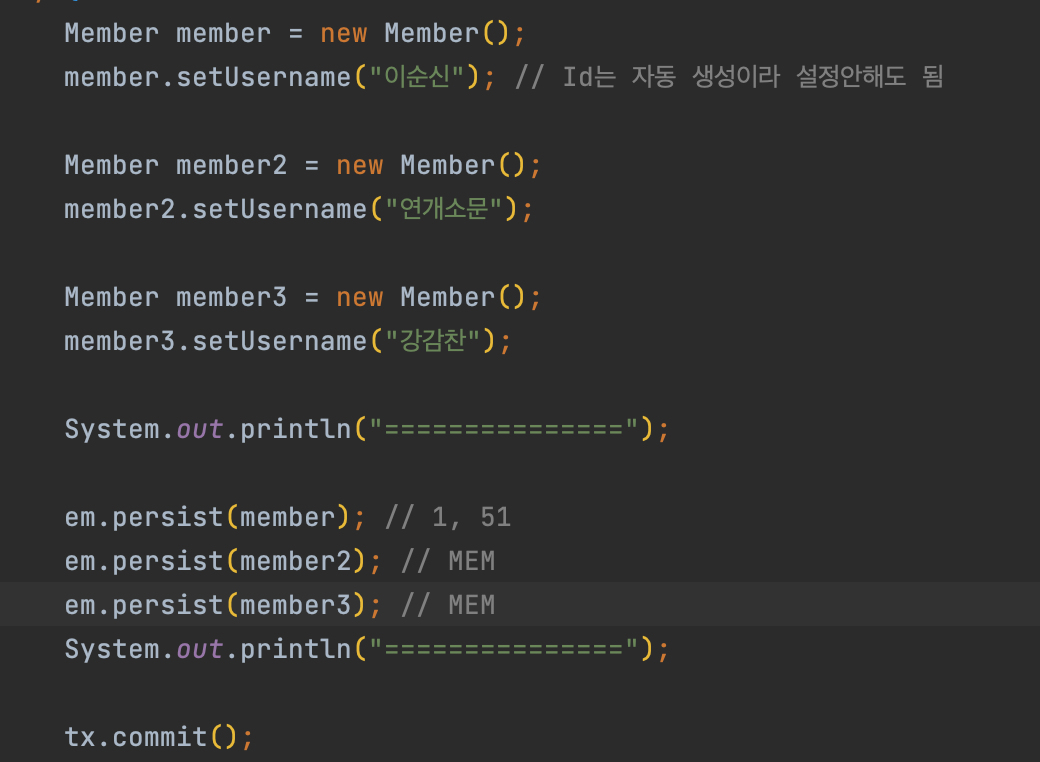

위 실행 결과처럼 처음에 1 그다음 51을 가져온 이후에 이후에는 가져오지 않고 메모리에 있는 것을 가져다 쓴다. (1~51 다 쓰면 이후에 다시 2번 select를 통해 다음값들을 가져오고 해당 값들을 사용) 이렇게 하면 성능에 조금 도움이 된다.
TABLE
쉽게 말해 데이터베이스 시퀀스 흉내 내는 전략이다. 그래서 모든 디비에 적용이 가능한데 성능이 단점이다.
@TableGenerator 어노테이션을 사용
'JAVA & SPRING > JPA' 카테고리의 다른 글
| JPA 기본편(프록시) (0) | 2024.03.04 |
|---|---|
| JPA 기본편0(연관관계 매핑 기초, 연관관계가 필요한 이유 & 연관관계 매핑) (0) | 2024.02.23 |
| JPA 기본편0 (엔티티 매핑) (0) | 2024.02.20 |
| JPA 기본편0 (영속성 컨텍스트 이점(2)) (1) | 2024.02.15 |
| JPA 기본편0 (영속성 관리, 영속성 컨텍스트 이점(1)) (0) | 2024.02.15 |


